
Immunocto: Automating Immune Cell Detection at Scale
Bridging the Gap Between Immunofluorescence and H&E Pathology
Understanding the tumor immune microenvironment (TIME) is crucial for predicting patient prognosis and treatment response, particularly with the rise of immunotherapy. However, identifying and classifying immune cells from routine hematoxylin and eosin (H&E) stained slides remains a significant bottleneck—manual annotation is time-consuming, and distinguishing immune cell subtypes by morphology alone is notoriously difficult, even for expert pathologists.
We're excited to introduce Immunocto, a massive database of 2.3 million immune cells that addresses these challenges through an innovative automated pipeline. More importantly, we're sharing both the methodology and the complete dataset with the research community.
The Core Innovation: Dual-Staining Strategy
The key insight driving Immunocto is leveraging the complementary strengths of two imaging modalities:
- H&E staining - the clinical gold standard, universally available
- Multiplexed immunofluorescence (IF) - provides definitive cell type identification through protein markers
By co-registering these modalities on the same tissue section, we create ground truth labels with unprecedented accuracy. This sidesteps the inter-observer variability that plagues manual annotation approaches—our expert review showed 89±4% agreement, substantially higher than previous datasets.
Technical Pipeline: From Millions of Candidates to Curated Dataset
Our workflow combines classical computer vision with modern deep learning:
Stage 1: Massive Candidate Generation
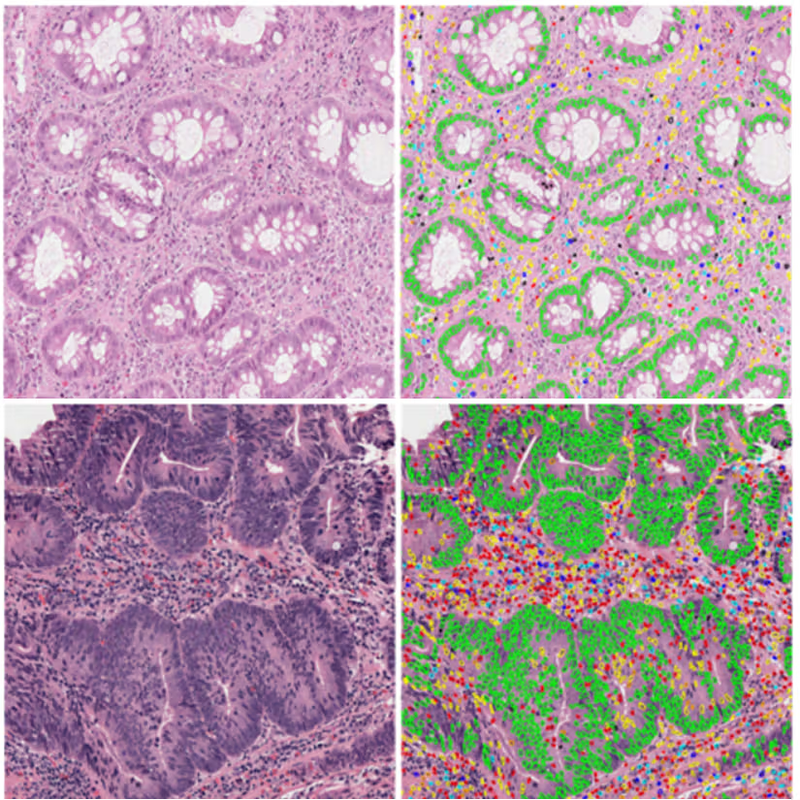
We deploy the Segment Anything Model (SAM) with ViT-H architecture on 40× magnification whole slide images (0.325 μm/pixel). Using a dense grid of point prompts (64×64 per 1024×1024 tile), SAM automatically segments over 54 million objects across 40 colorectal cancer patients. Importantly, we show that SAM outperforms fine-tuned variants (MicroSAM, CellSAM, CellViT) for lymphocyte detection, achieving 0.762 DICE score and 0.981 recall on the Lizard test set.
Stage 2: IF-Guided Classification
From these millions of candidates, we apply an iterative thresholding scheme on 18 IF channels following a decision tree adapted for colorectal cancer. This automatically extracts candidates for:
- CD4⁺ T cells
- CD8⁺ T cells
- CD20⁺ B cells
- CD68⁺/CD163⁺ macrophages
Stage 3: Bootstrap Training
An initial 20,000 candidates undergo manual review to create Immunocto V₀. We then train a ResNet50 classifier on 12-channel inputs (RGB H&E + 8 IF channels + binary mask), achieving >98% validation accuracy per class.
Stage 4: High-Confidence Expansion
Applying this classifier across all 40 WSIs and retaining only predictions with ≥95% softmax probability yields the final Immunocto V₁: 2,282,818 immune cells plus 4.5 million non-immune cells for discrimination.
Validation: Quality at Scale
We implemented three complementary validation strategies:
Clustering Analysis: Linear classifiers trained on pairwise IF channel distributions show only 0.51% of cells fall into ambiguous regions between subtypes—demonstrating clean class separation in the IF space.
Expert Review: Two independent pathologists reviewed 1,000 randomly sampled cells, achieving Cohen's κ=0.75 inter-rater agreement (higher than Lizard's 0.61-0.67) and 89% average concordance with Immunocto labels.
Segmentation Benchmark: SAM achieved superior recall (0.981) compared to specialized models on external datasets, validating our segmentation approach.
Performance: State-of-the-Art Results
Models trained on Immunocto demonstrate substantial improvements:
Internal Testing (Orion hold-out patient)
Our SAM+ConvNet architecture with 256×256 context windows achieved:
- Lymphocyte detection: F₁=0.95
- B cell subtyping: F₁=0.79
- CD4⁺ T cell subtyping: F₁=0.65
- Macrophage detection: F₁=0.77
External Generalization
Despite being trained exclusively on colorectal cancer, Immunocto-trained models substantially outperform HoVer-Net trained on the pan-cancer Lizard dataset:
- SegPath test set recall: 0.67 vs 0.45 (49% improvement)
- Immunocto test set recall: 0.94 vs 0.08 (>10× improvement)
This demonstrates that dataset size and label quality trump tissue diversity for lymphocyte detection—likely because lymphocyte morphology is conserved across cancer types.
Technical Considerations and Limitations
Registration precision: We use 30% of Otsu's threshold on the Hoechst channel to compensate for IF/H&E registration errors—a practical consideration for multi-modal imaging.
Macrophage complexity: These cells showed the lowest expert agreement (84±6%) due to their morphological heterogeneity and phagocytic activity variations. This highlights an inherent biological challenge rather than a dataset limitation.
Cell coverage: Currently limited to four immune subtypes. Expanding to neutrophils, plasma cells, eosinophils, and fibroblasts would enable more comprehensive TIME characterization.
Impact and Future Directions
Immunocto represents a paradigm shift in how we create training data for computational pathology:
- Minimal manual annotation: ~20,000 reviewed cells generate 2.3 million high-quality labels
- Objective ground truth: IF-based labels avoid morphology-dependent biases
- Unprecedented scale: 16× larger than previous immune cell datasets
- Lymphocyte subtyping: First dataset enabling CD4⁺/CD8⁺/CD20⁺ discrimination on H&E
The methodology is generalizable—any cell type with specific IF markers can be extracted using this pipeline. We envision extensions to other tissue types, additional immune populations, and integration with spatial transcriptomics data.
Open Science
The complete dataset (6.8 million cells with 64×64 pixel H&E images and binary masks) is freely available at Zenodo, and our code is accessible on GitHub.
By sharing these resources, we hope to accelerate research in computational pathology, enable more accurate biomarker discovery, and ultimately improve patient stratification for immunotherapy.
Citation: Simard M, Shen Z, Bräutigam K, Abu-Eid R, Hawkins MA, Collins-Fekete CA. Immunocto: a massive immune cell database auto-generated for histopathology. arXiv:2406.02618v2 [q-bio.QM], 2025.
Correspondence: c.fekete@ucl.ac.uk
Funding: UKRI Future Leaders Fellowship (MR/T040785/1), Cancer Research UK (C7893/A28990), UKRI AI for Health (EP/Y020030/1)
